圧縮の仕組み

圧縮とは,デジタルデータの内容を保ちながらデータ量を減らすことです。 データを圧縮することで,通信時に短い時間で転送することができます。
圧縮するとデータ量が小さくなるのか。圧縮ってすごいなぁ。

もとにもどせるように圧縮するのは大変そう。大きいものを小さくしたらもどらなくなりそうですが・・・。


そうですね。 圧縮には二つの種類があります。 一つは「可逆圧縮」と呼ばれ,圧縮前の状態に完全にデータをもどすことができるものです。 もう一つは,圧縮前の状態に完全にデータをもどすことができない「非可逆圧縮」と呼ばれるものです。 可逆圧縮は,圧縮したデータをもどすことができるかわりに,一般的に非可逆圧縮よりもデータが大きくなります。 圧縮したデータをもとにもどすことを「解凍する」「伸張する」と呼ばれます。

「展開する」ともいいますが,これはZIPファイルなど,複数のファイルをまとめて圧縮された一つのファイルを,個々のファイルにばらして解凍することをいいます。
「ファイルを展開してください」って聞いたことあるね。


そうですね。では,ファイル形式について学んでいきましょう。
ファイル形式と圧縮
2人は「拡張子」という言葉を聞いたことがありますか?
ファイルの拡張子という使われ方をしますよね。

動画や画像のファイル名の「.」のあとについているものですね。


その通りです。 ファイルの拡張子は「そのファイルがどのようなデータなのか」ということを示しています。 たとえば,「.wav」という拡張子がついているファイルは,WAVEのファイル形式のデータであることがわかります。 まず,音のファイル形式についてみていきましょう。音のファイル形式には以下のようなものがあります。
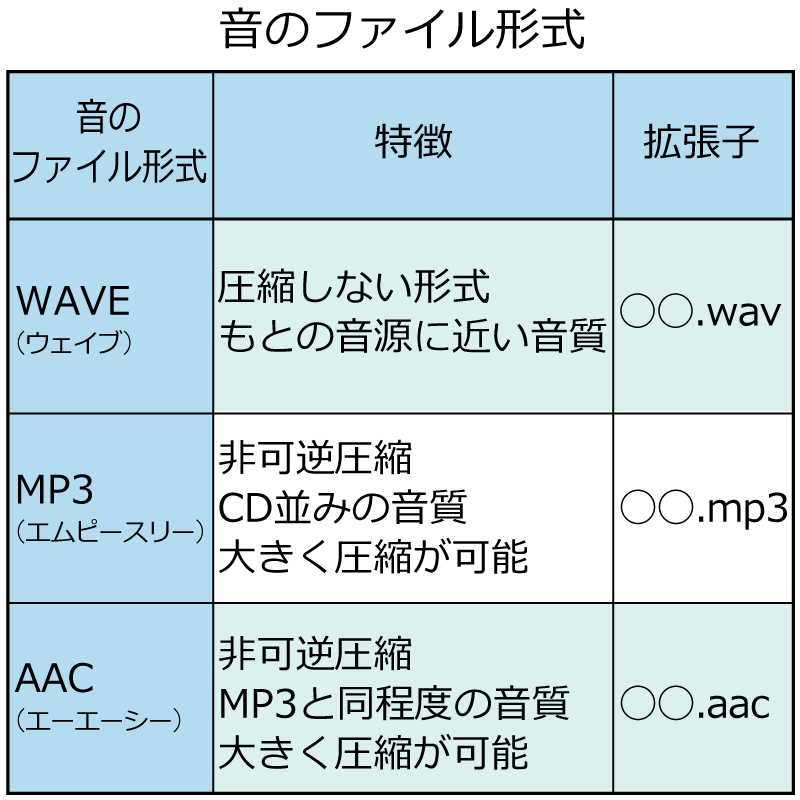
MP3とWAVEは聞いたことがあります。

WAVEの方が音質はよかったのか。

画像についても同じく,拡張子でファイル形式がわかります。
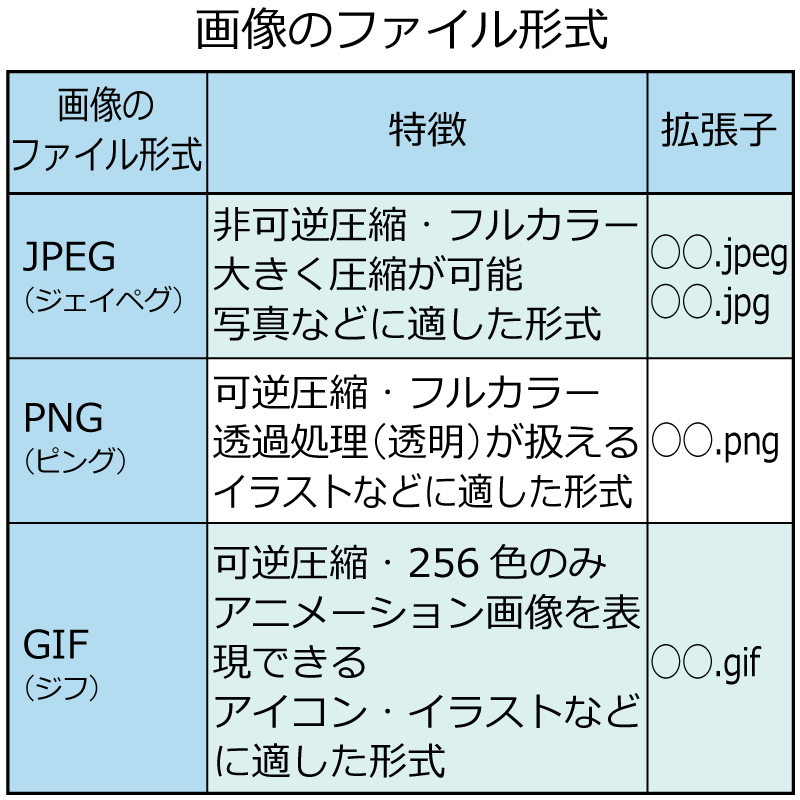
どれも聞いたことがあります。

いろいろな画像のファイル形式があるのですね。


はい。ここでは紹介しきれなかった音・画像のファイル形式はたくさんあります。 それぞれ特徴が違い,圧縮の有無や方法も違うので,使用用途に合わせて形式を変えてみてください。
可逆圧縮の具体的な例と圧縮率(ランレングス法)
では,可逆圧縮の仕組みがどうなっているのか,具体的な方法をみてみましょう。ここでは,「ランレングス法」を学んでいきます。
ランレングス法?難しそうだ・・・。
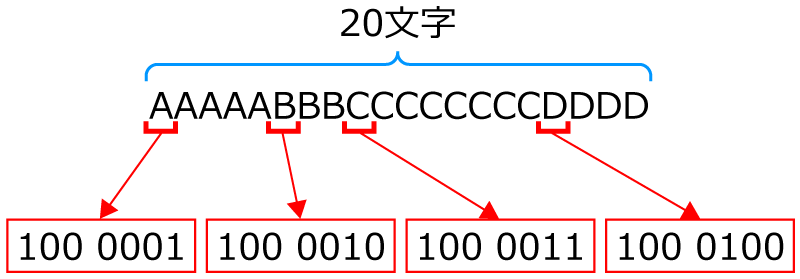
やってみると,そんなに難しくないですよ。たとえば,こんな文字列があったとします。
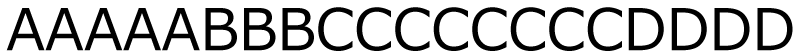
このなかの,同じデータの数に着目して圧縮していきます。同じデータの数を数えてみましょう。
A~Dがそれぞれいくつあるか,ってことですか?

はい,そうです!
Aが5個,Bが3個,Cが8個,Dが4個です。
全部で20文字ですね。
そうですね! 連続で並んでいる文字の個数で整理して,圧縮すると,こんな感じになります。
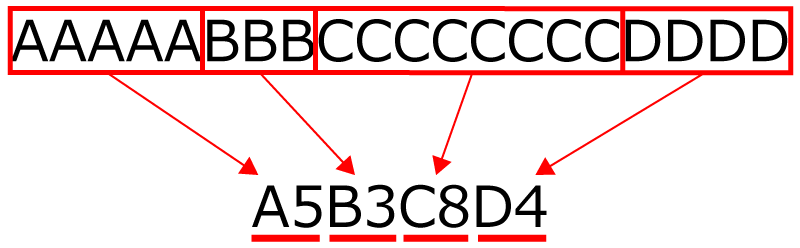
おお!
これだと,データの個数がわかるから,もとにもどせます!
ということは,可逆圧縮ですね!!
その通りです!いいですね! じゃあ,同じ考え方で,次の文字列を圧縮してみてください。
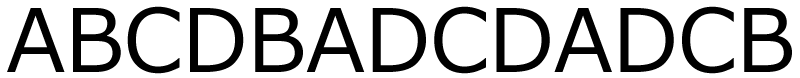
あれ?連続している部分がない・・・。
データの後ろに個数をつけるとすると,こうなります!
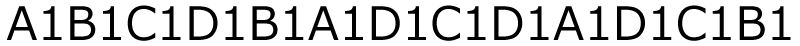
長くなってるー!!
そうなんです! ランレングス法の考え方では,連続したデータがない場合,圧縮できないことがあります。 ※実際は連続したデータがない場合は,数字部分を省略する仕組みもあります。ただ,その場合ももとのデータと変わらないですね。
なるほど!
連続したデータがあるほど,圧縮する意味がある方法なんですね。
そうです!その通りです。 興味があったら,ランレングス法がどんなところで使われているか調べてみてください。
はーい。
では,少し話題を変えまして,ここで,「圧縮率」についても,学んでいきましょう。
圧縮率?
「圧縮率」とは,もともとのデータ量に対して,圧縮したデータがどれくらいのデータ量になったかを示す数値です。
ほお・・・?
難しいな・・・。
実際にやってみましょう! 今から行う手順は,
1. もとのデータのデータ量を求める。
2. 圧縮されたデータのデータ量を求める。
3. 圧縮率を求める。
よし!やってみよう!
今回は先ほどのデータで考えてみます。
まず「1. もとのデータのデータ量を求める。」ですね。ABCDを文字コードに置き換えて,圧縮前のデータ量はどれだけだったのかを確認しましょう。
「文字のデジタル化」のときに学んだASCIIコードで考えてみましょう。コード表は1部抜粋したものです。これを使ってみてください。
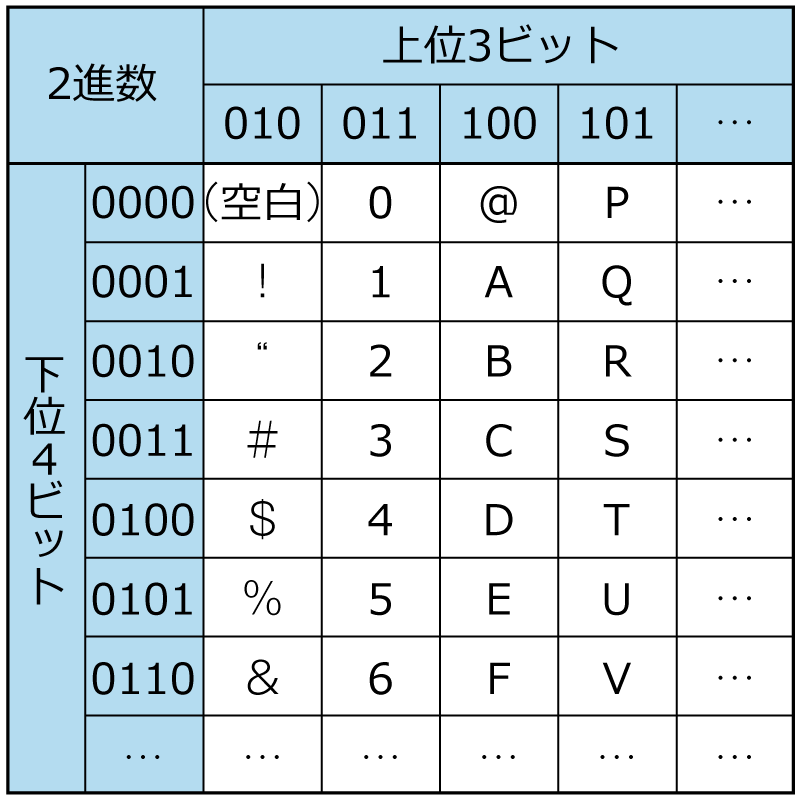
こんな感じで,A・B・C・Dそれぞれ7ビットになりました。
ふむふむ。
その通り!
1文字7ビットで,20文字あるので,
7ビット×20文字=140ビット
これで,もとのデータのデータ量は140ビットになることがわかりました。
なるほど・・・。
次に「2. 圧縮されたデータのデータ量を求める。」に入ります。 ここで,圧縮後のデータのデータ量を考えていきますよ! このデータを圧縮したら,どうなりましたか?
こうなりました!
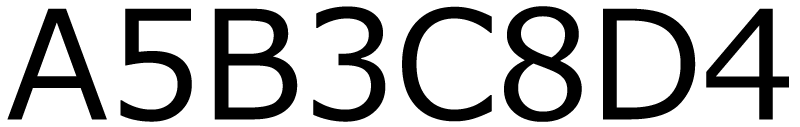
A~Dのそれぞれのデータの個数は何個になりますか?
Aが5個,Bが3個,Cが8個,Dが4個ですね!圧縮後のデータのアルファベットのあとについている数字です!
その通りです!圧縮後のデータ量を求める,ということで,次は各アルファベットの個数の情報を2進法の数字で表すことが必要になります。
なるほど,次は5・3・8・4を2進法にするんですね!
そうです!! 今回の2進法にしなければならない数字のなかで最大は8ですね。 8までの数を2進法で表すとき,何ビット必要でしょうか?
8は2進法で1000でしたよね・・・。
じゃあ,4ビットです!

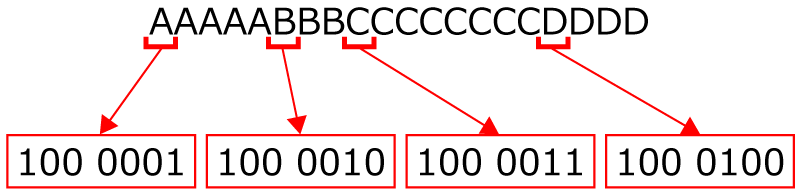
正解です!! A5B3C8D4のデータを2進法で置き換えると,下の図のようになります。
そっか,なるほど。A~Dはさっきの文字コードが使えますね。
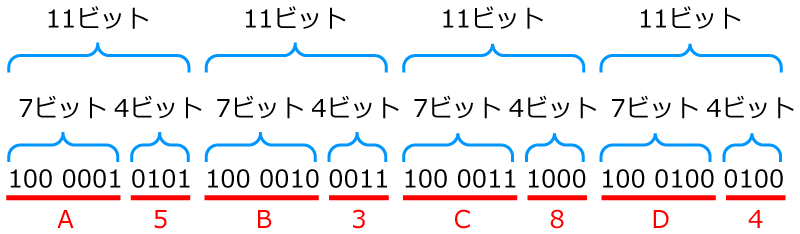
じゃあ,A5は11ビットで表現できてますね。 ほかのB・C・Dについてもそれぞれ11ビットですね!
じゃあ,圧縮後のデータ量は,全部で11×4で44ビットです!!
いい感じですね!
おお!140ビットから44ビットに減りました!!
ここで圧縮率が出せます! 「3. 圧縮率を求める。」です。 下の式で,圧縮率を求められます。

わかった!
44 ÷ 140 x 100 ≒ 31.4
じゃあ,圧縮率は31.4%だったんですね。
正解です! いろいろ手順を踏んできましたが,覚えてほしいのは,圧縮前後のデータ量から,どれだけデータが圧縮されたかを求めることができるということです。 先ほどの,式の考え方やつくり方をおさえておきましょう。
はーい。
【応用編】ハフマン符号化
応用編として別の圧縮方法も学んでいきましょう。
今度はどんな圧縮方法ですか?
ハフマン符号化といいます。 データの出現頻度に応じて,出現頻度が高いデータには短いビット列,出現頻度が低いデータには長いビット列に符号化(置き換え)をして変換していく方法です。
難しくて,よくわからないな・・・。
具体的にやってみましょう! 今回は,こんな文字列を圧縮していきましょう。

1文字7ビットとします。 何度も出てくるデータと,そんなに出てこないデータがあるのがわかりますか?
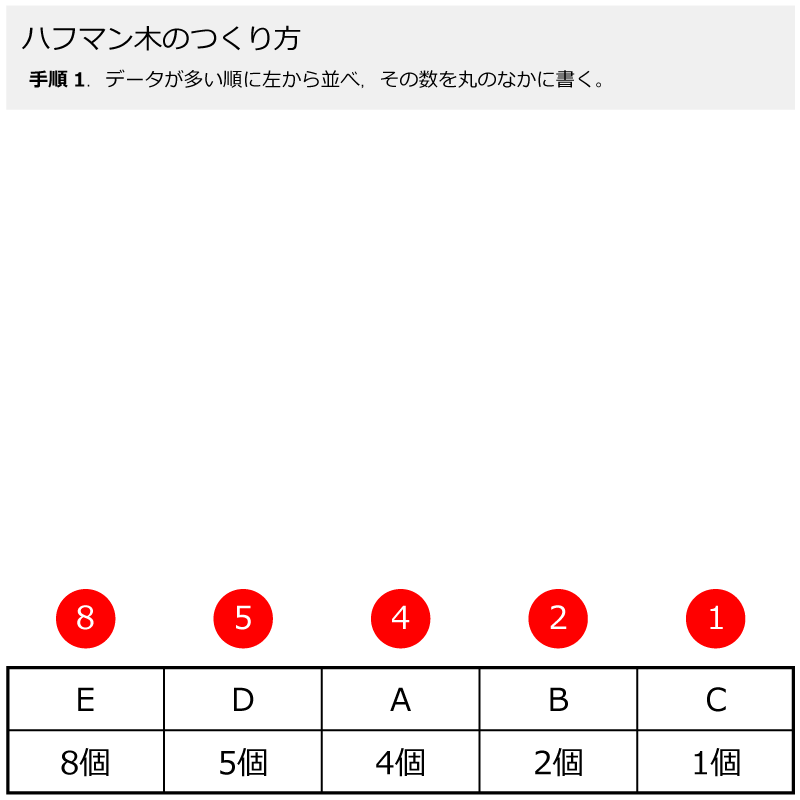
Aが4個,Bが2個,Cが1個,Dが5個,Eが8個ですね。
Eがたくさん出てきて,Cが1回しか出てきてないです。
そうです! たくさん出てくる「E」のデータをより小さく圧縮すれば,効率的に圧縮ができると思いませんか?
なるほど!たしかに!
データをある規則にしたがって別の値に置き換えていくことを「符号化」といいます。 今回はより数が多いデータを小さなデータに符号化する圧縮方法を学んでいきます。
おお,ちょっとわかった気がします!
この圧縮方法は次のように行います。
1. それぞれのデータの量を把握する
2. データ数が大きい順番に並べ替える
3. 符号化のための図を使って,データを符号化する
4. データを符号化にしたがって置き換える
ふむふむ
1. それぞれのデータの量を把握する
これは先ほどできましたね!
はい!
Aが4個,Bが2個,Cが1個,Dが5個,Eが8個です。
次は「2. データ数が大きい順番に並べ替える」です。 データの数が大きい順に並べてみます。

うん,うん!楽勝!楽勝!!
ここからが本番です!!
「3. 符号化のための図を使って,データを符号化する」
ですね!「ハフマン木」という図を使って符号化していきます!
符号化するための図のことです。つくり方は,これをみてください。 一緒に手順を追っていきましょう!

おおお・・・なんか難しい・・・。
手順を一緒にやっていくと,そんなに難しくないですよ!
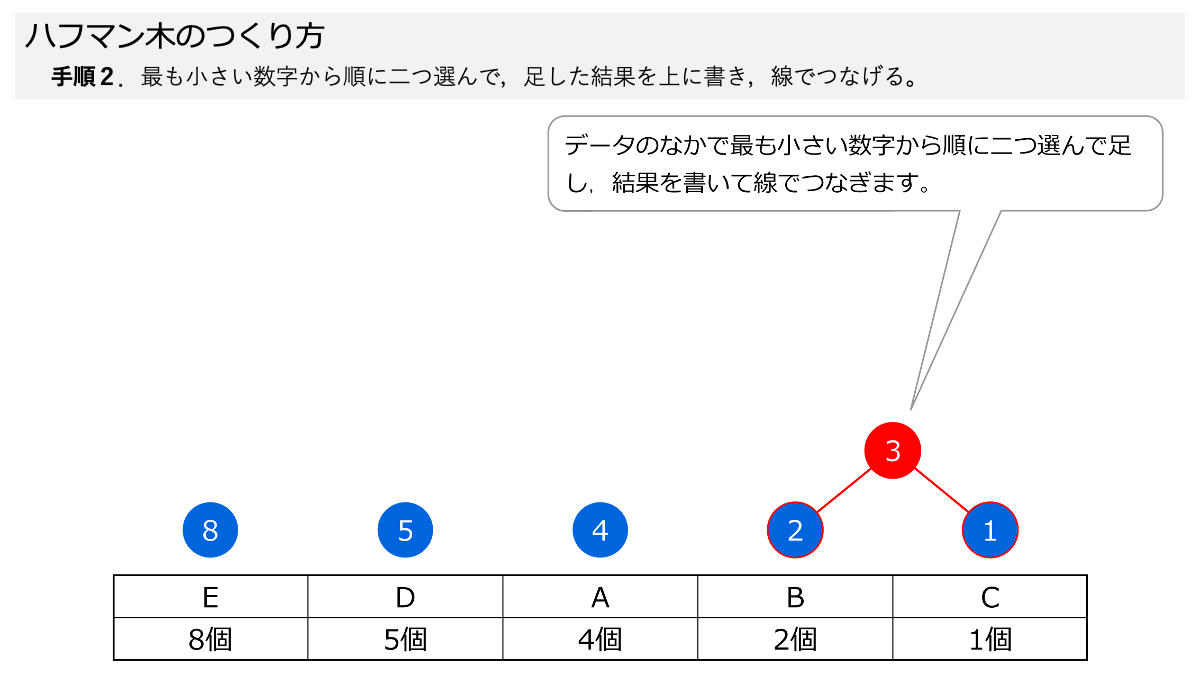
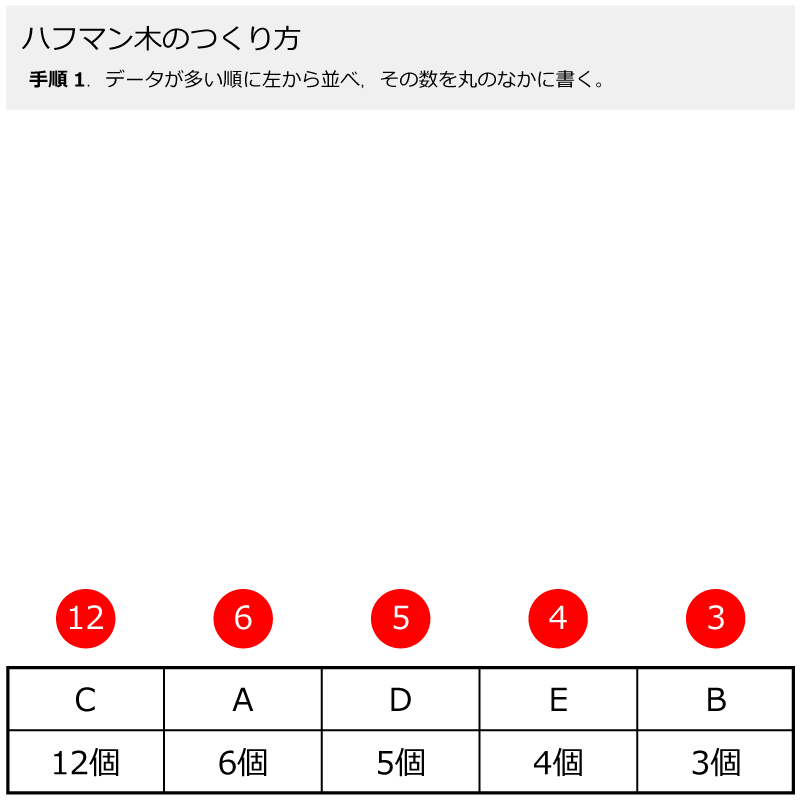
まずは,手順1で,データの個数ごとに,大きい順番に左から並べます。
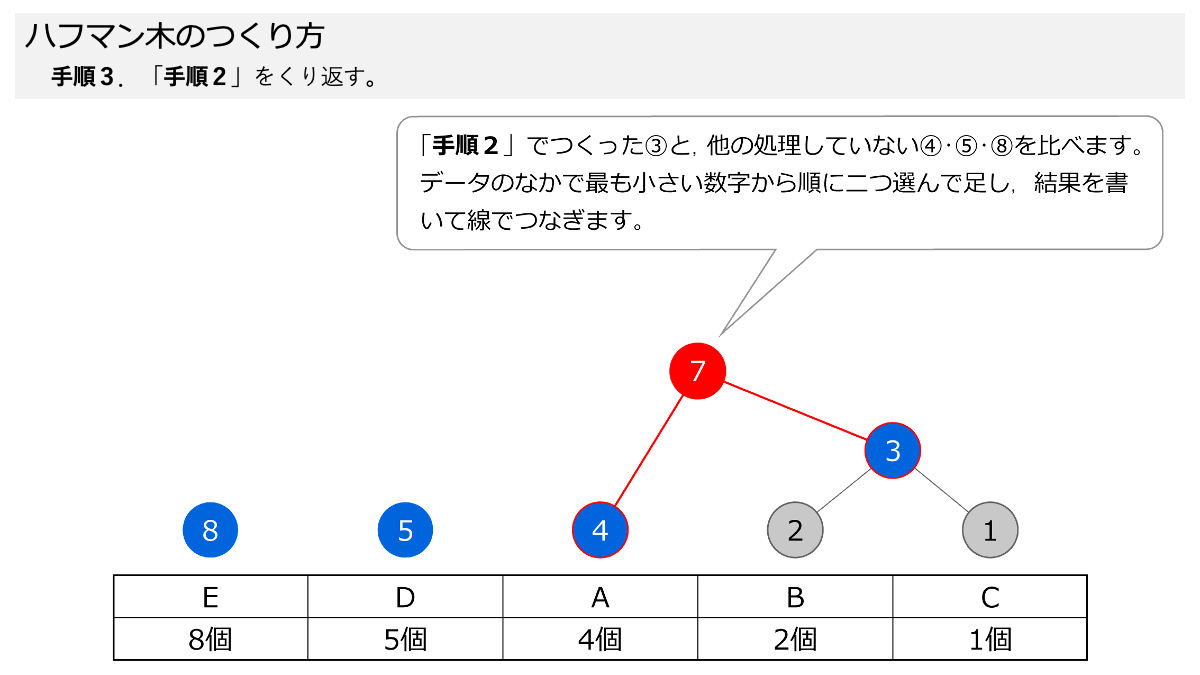
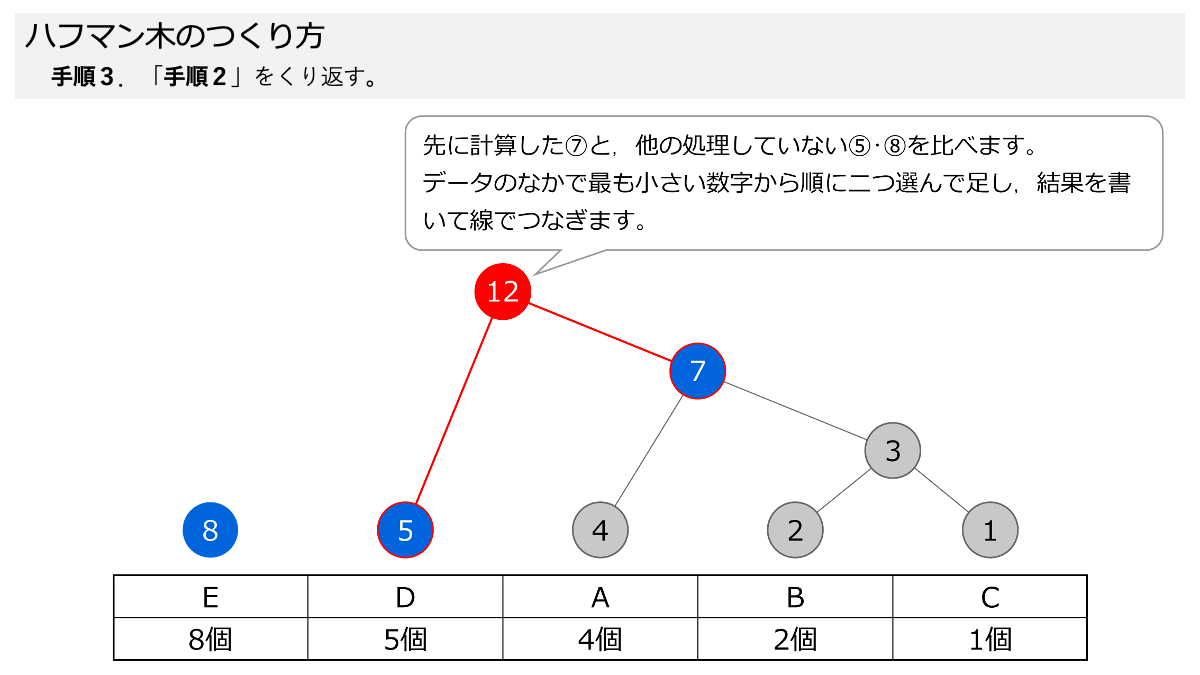
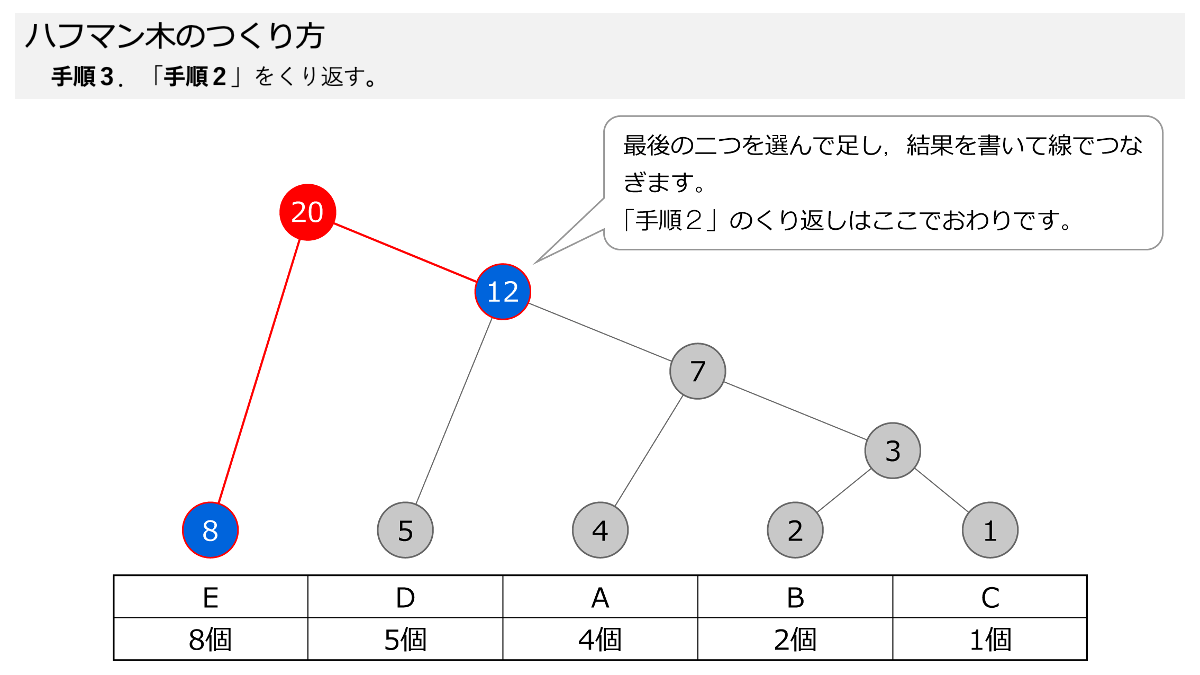
次に,小さい数字を二つ選んで足していく作業をくり返します。手順2と手順3です。 スライド形式になっていますので,ページをめくって手順を追っていきましょう。
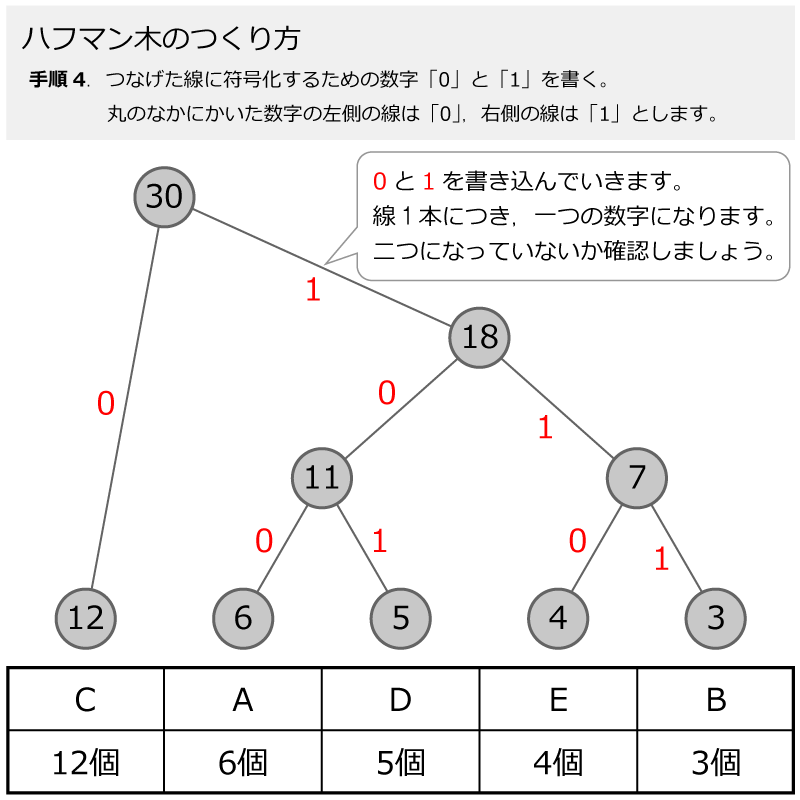
そして,先ほど引いた線に,符号化のための「0」と「1」をつけていきます。手順4で,数字の丸の左側の線に「0」,右側の線に「1」を書きます。 ここもスライド形式になっていますので,ページをめくって手順を追っていきましょう。
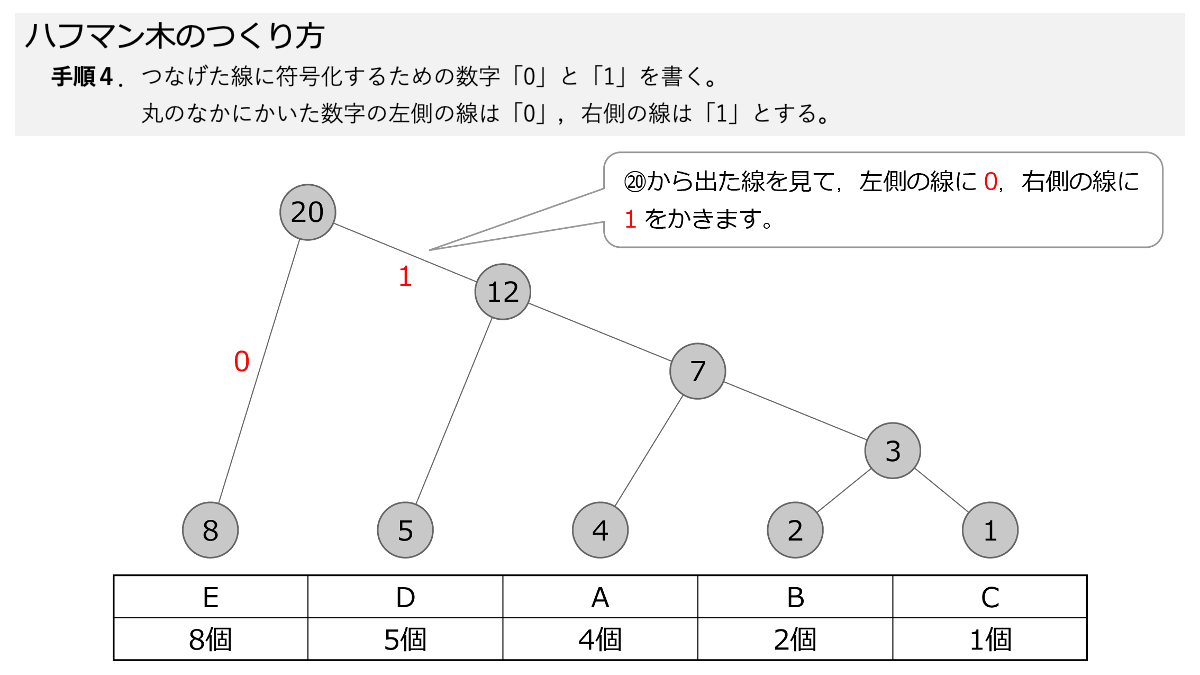
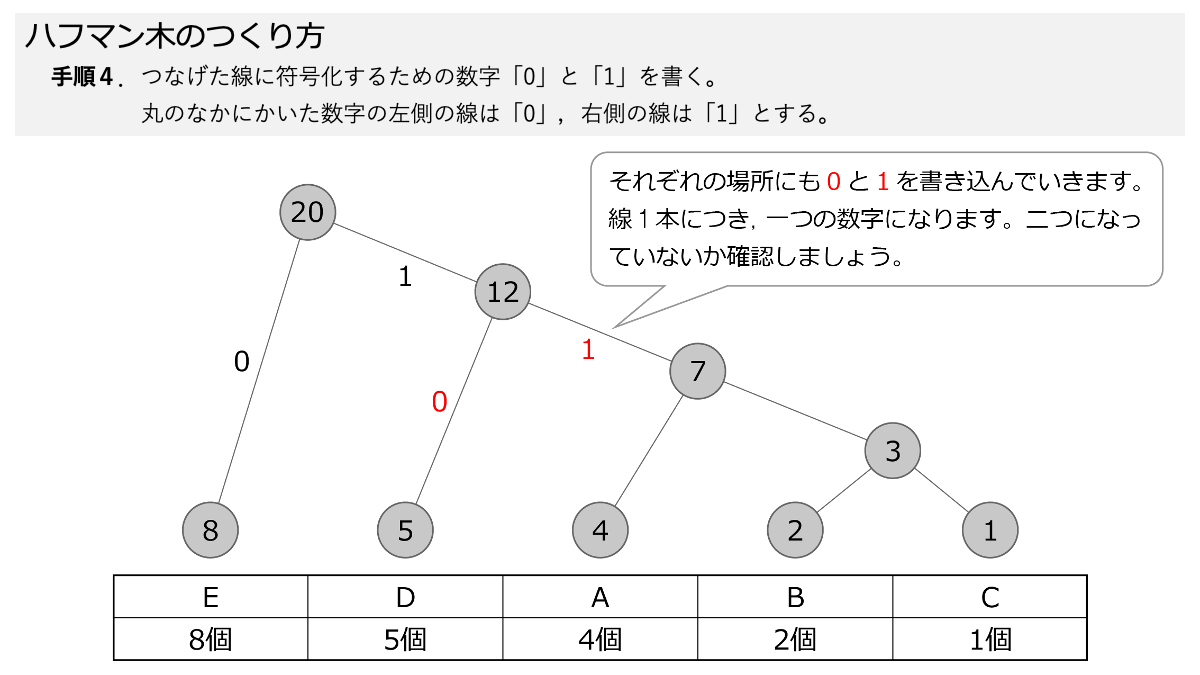
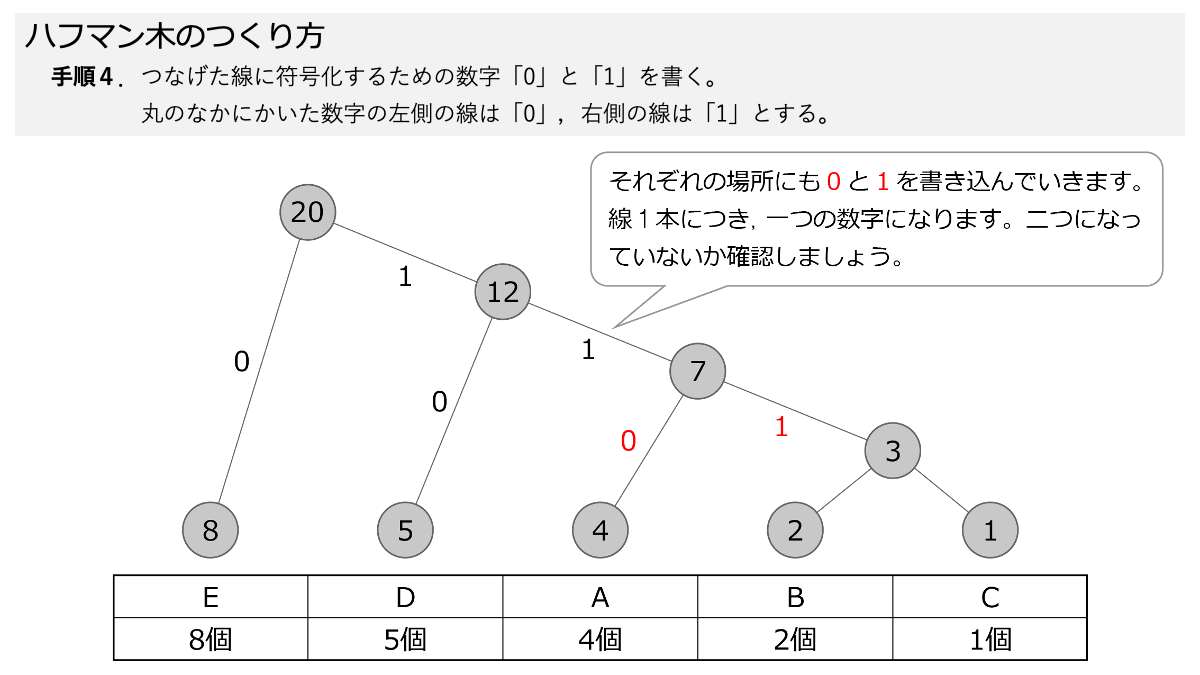
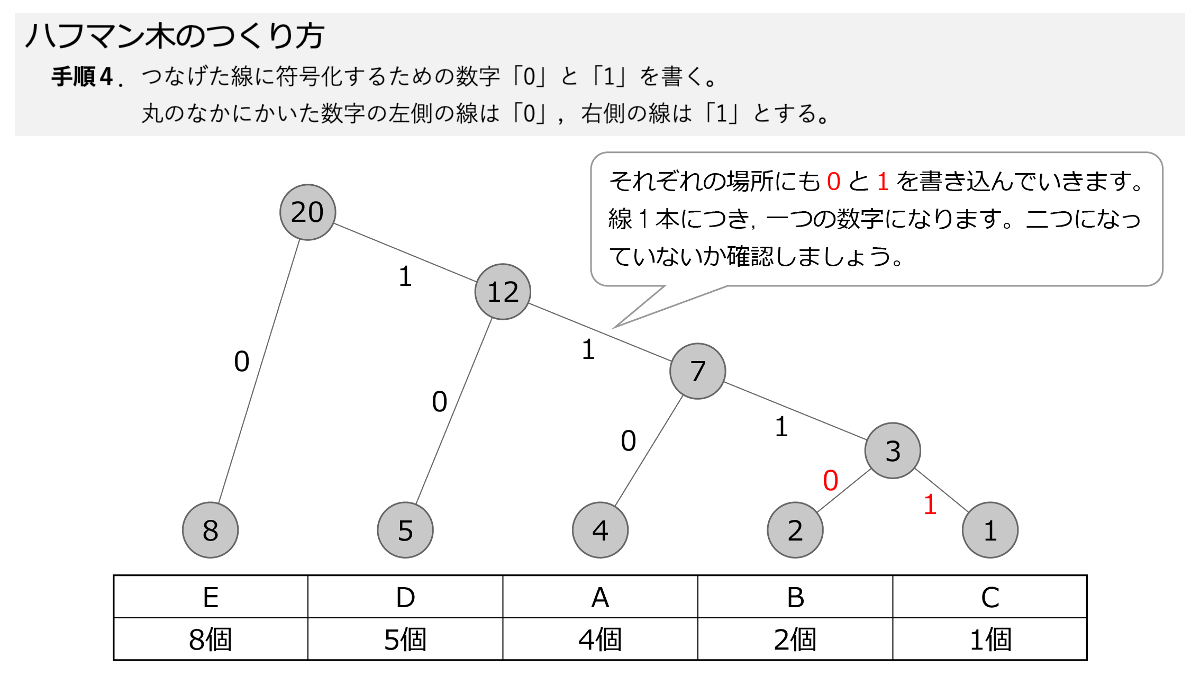
これでハフマン木が完成しました。
木,というか根っこみたいですね・・・。

ひっくり返っていますが。一つの数字の丸から枝分かれしていく様を「木構造」として表現しています。
ふむふむ。
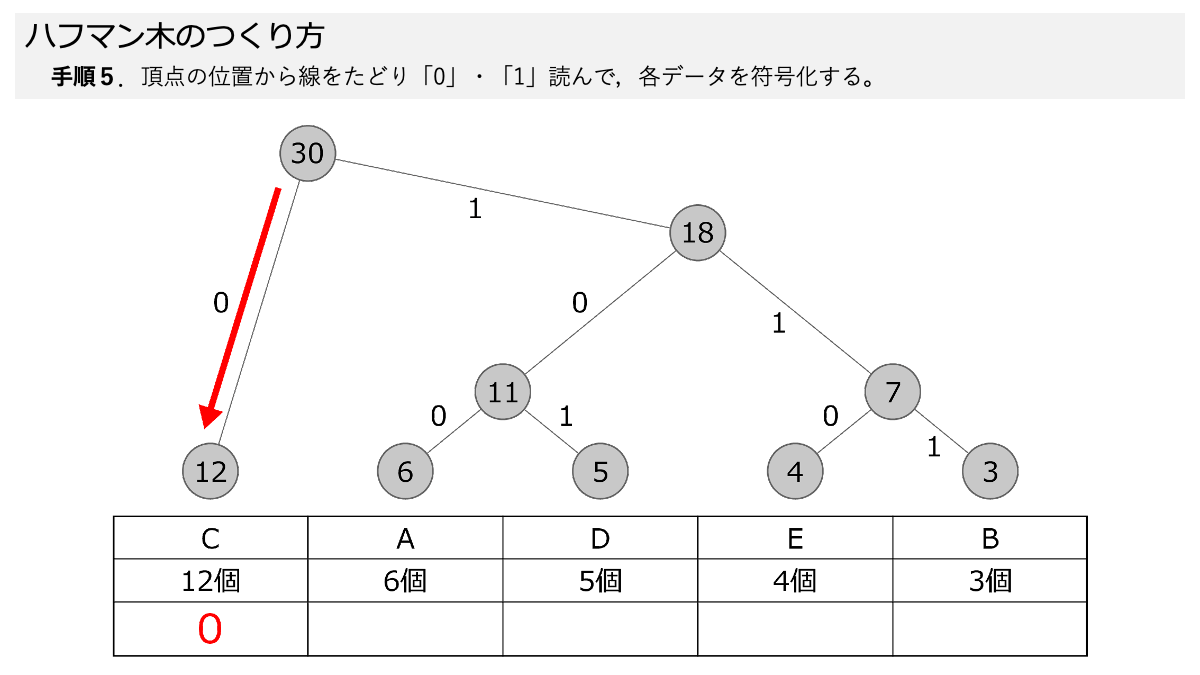
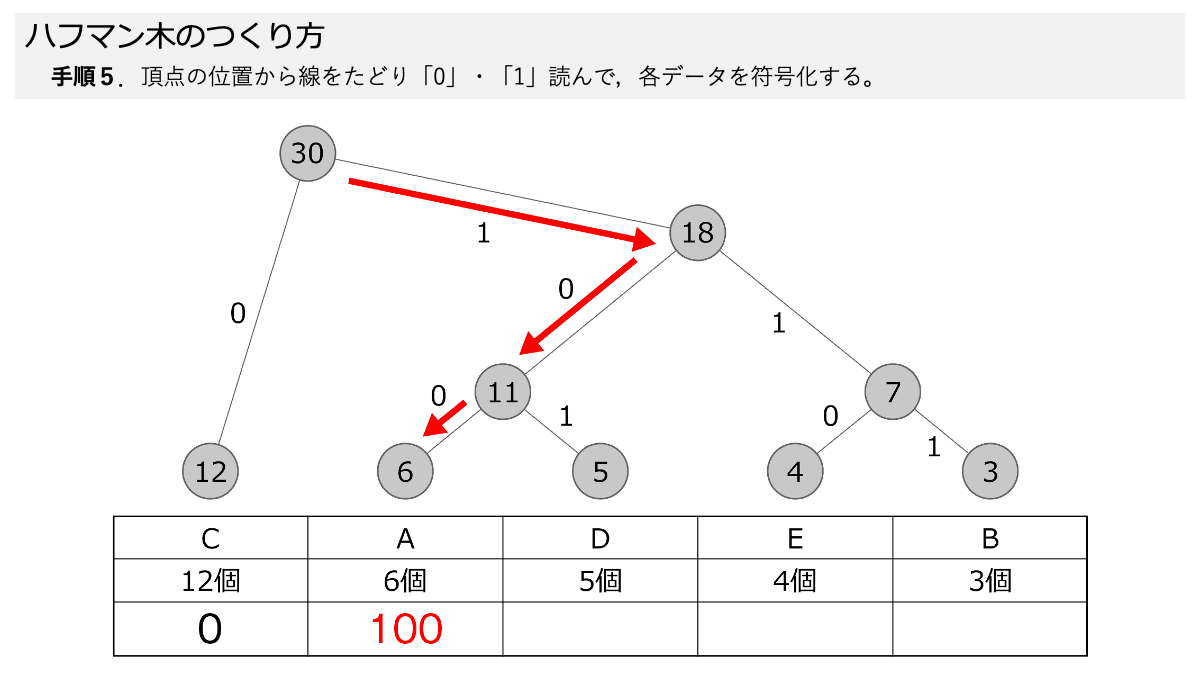
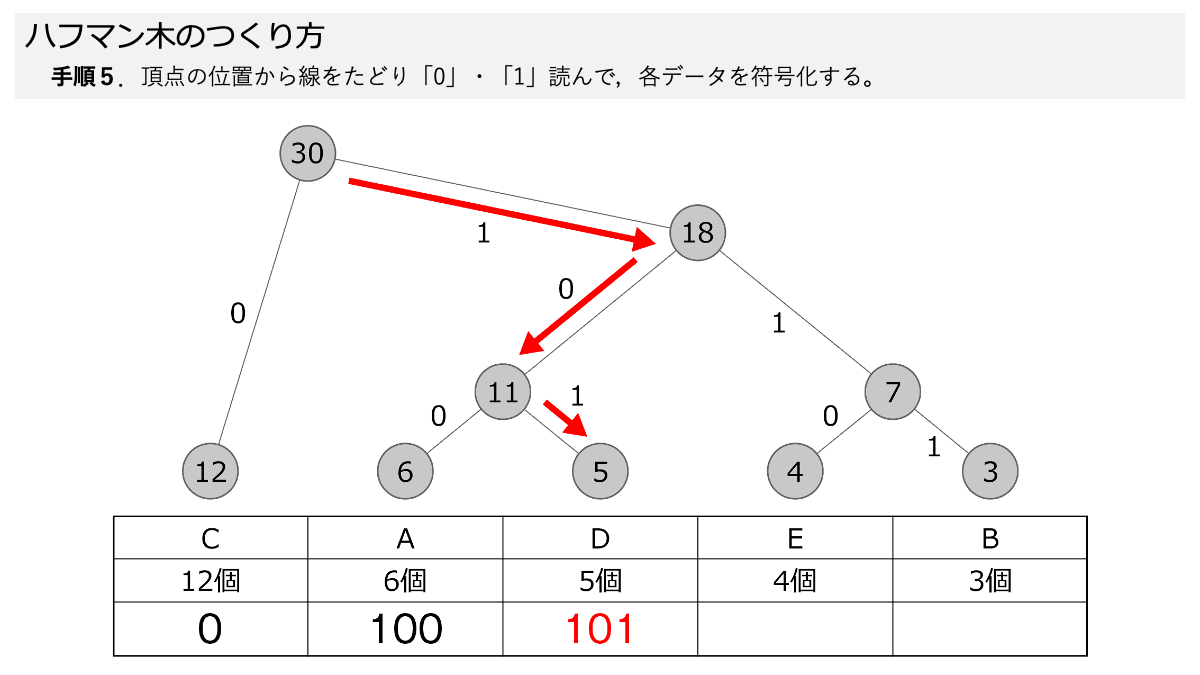
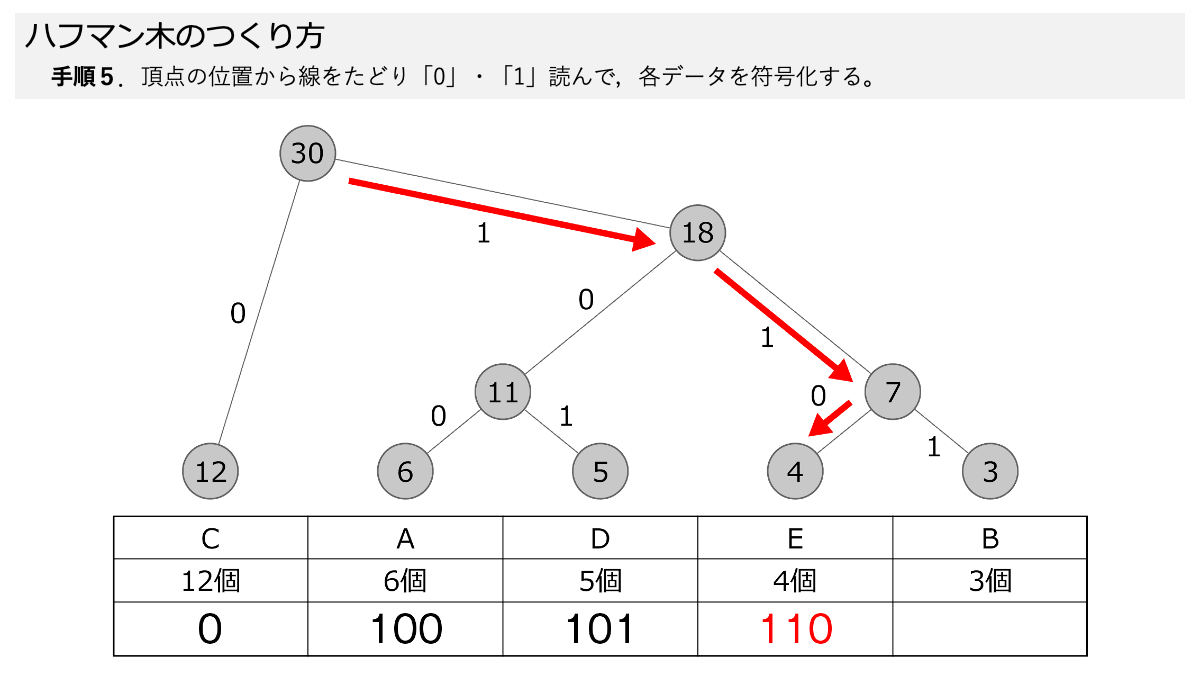
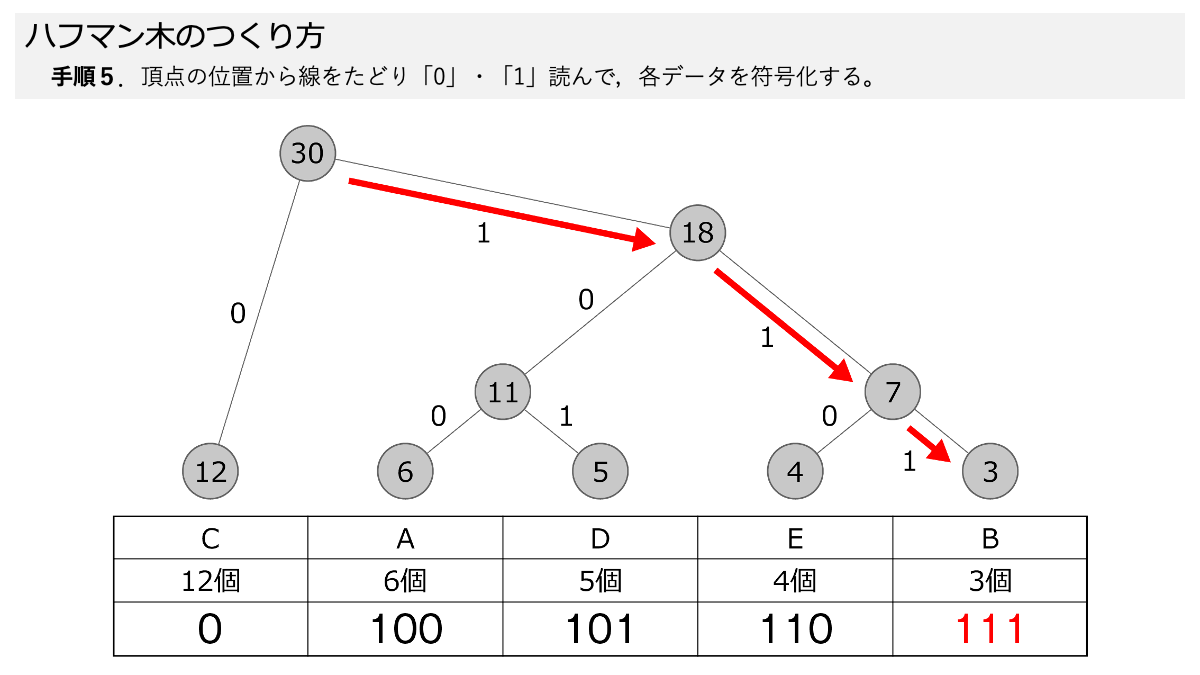
ハフマン木ができたので符号化していきますよ!手順5で,線を上から,下にある各データまでたどって,線の「0」と「1」を読んでいきます。 ここもスライド形式になっていますので,ページをめくって手順を追っていきましょう。
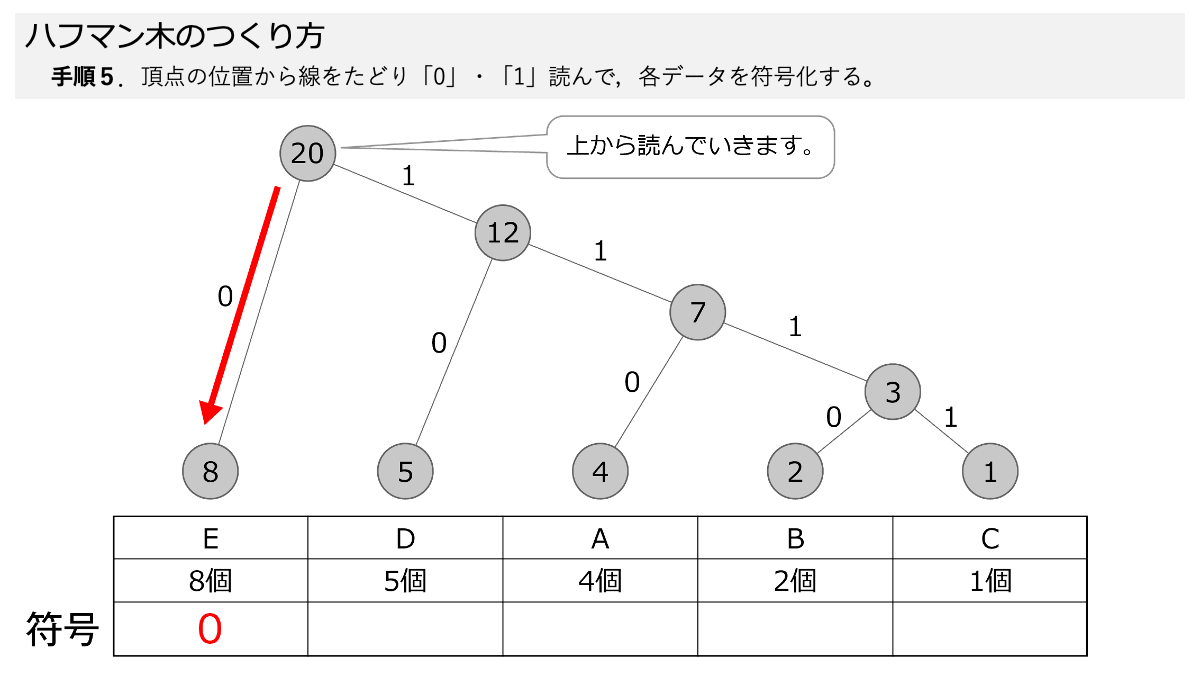
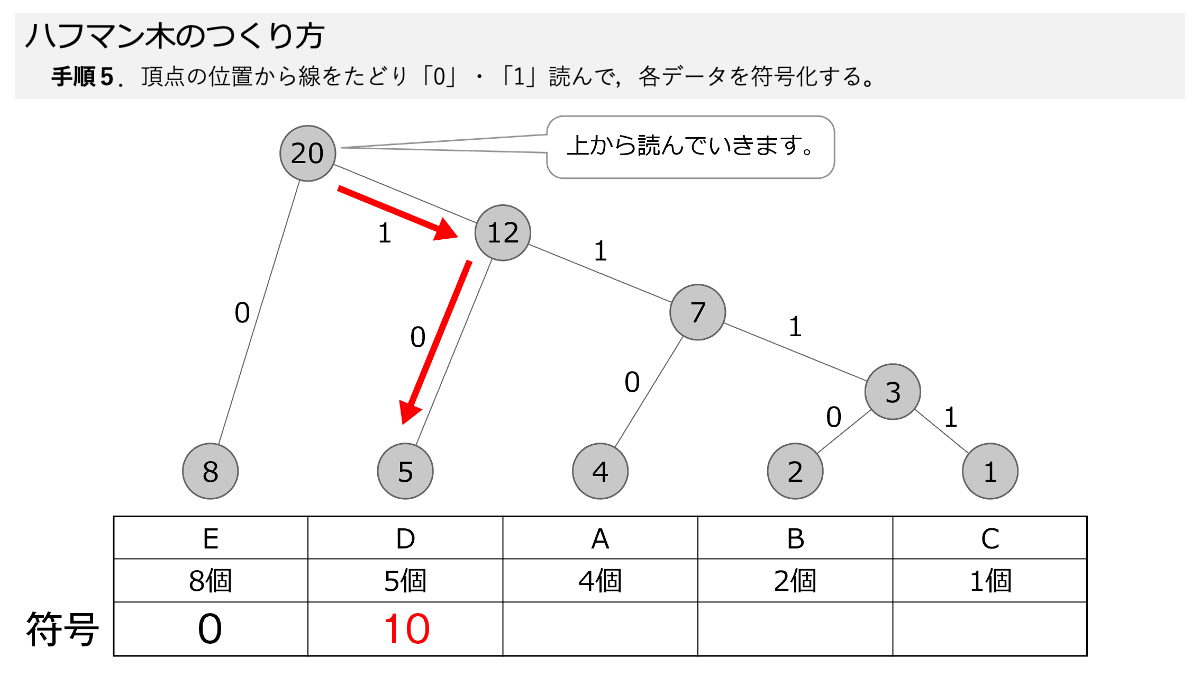
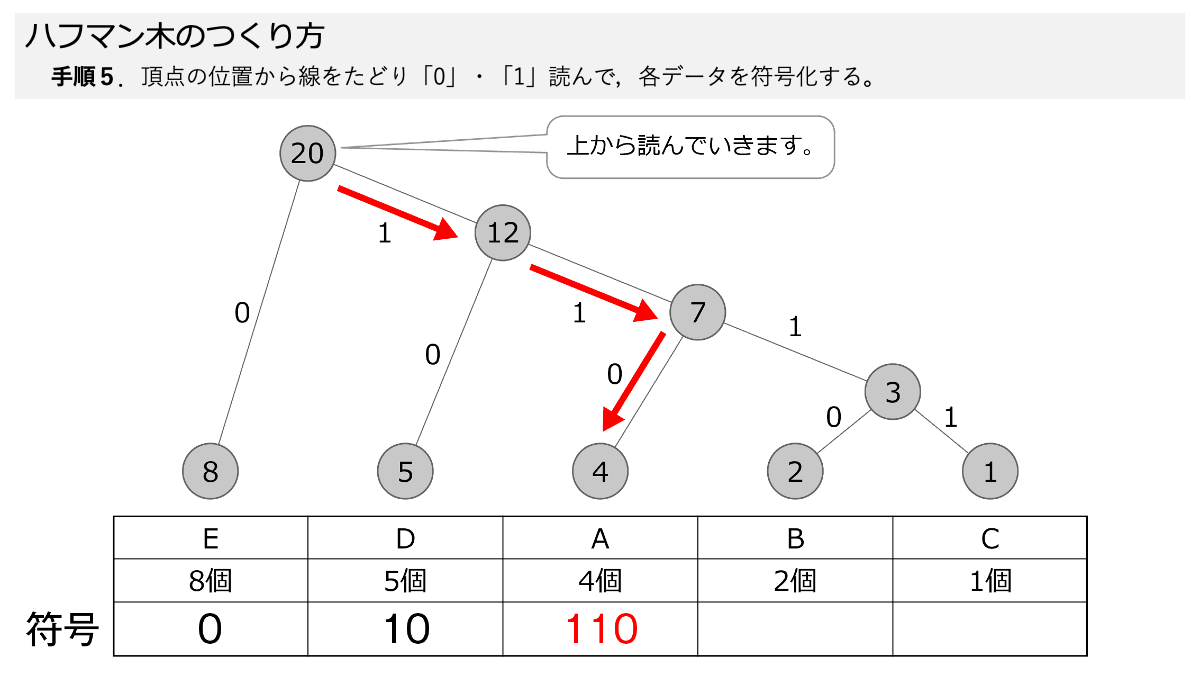
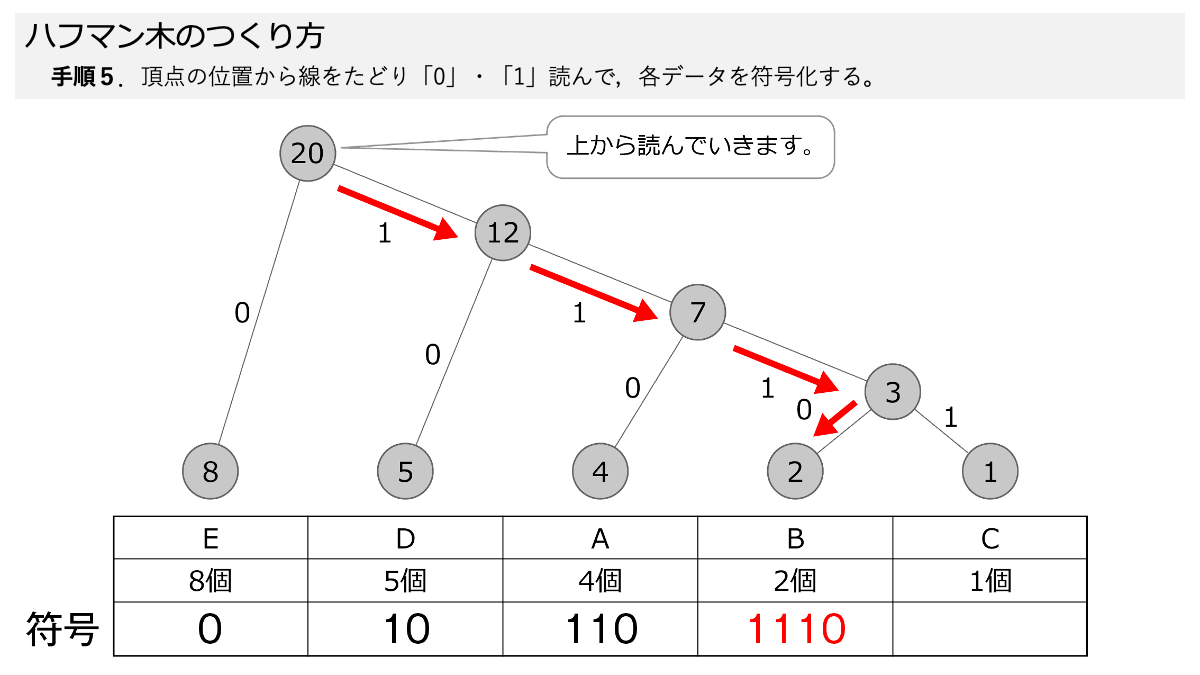
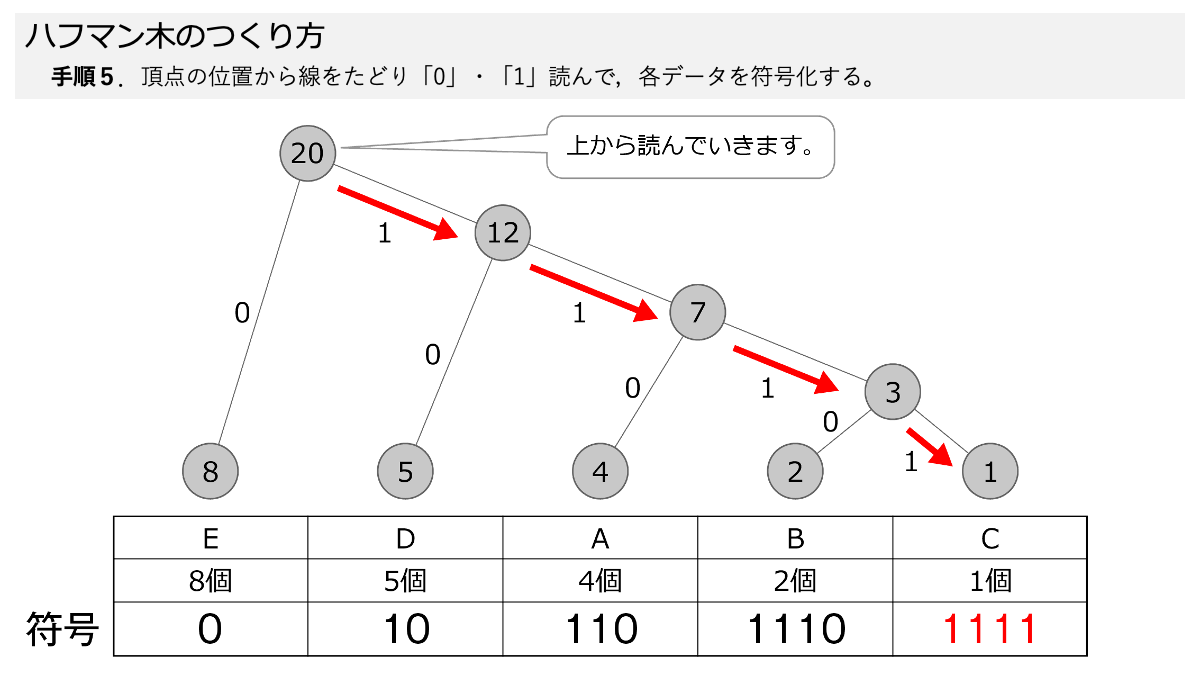
おぉ!これでEが「0」だけで表すことができるってことですか?
その通りです! 表のように符号化することで,A~Eをそれぞれデータ量に応じて符号化しました。 ここで「3.符号化のための図を使って,データを符号化する」の手順1~5の符号化する手順が終わりです!
あとは「4.データを符号化にしたがって置き換える」の置き換えですね!
はい! 「4.データを符号化にしたがって置き換える」は 「3.符号化のための図を使って,データを符号化する」で符号化したデータに置き換えていきます。
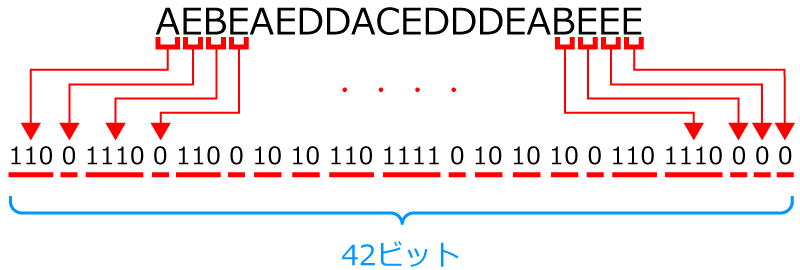
140ビットが42ビットになりました!
圧縮率30%になります!!
そうですね!! ちなみに,これは可逆圧縮・不可逆圧縮のどちらでしょうか?
符号化された表があればもとにもどせますよね?
じゃあ,可逆圧縮ですね!!
お見事!!正解です! どの文字が,どんな符号に置き換わっているかがわかれば,もとにもどすことができますね!
はい!
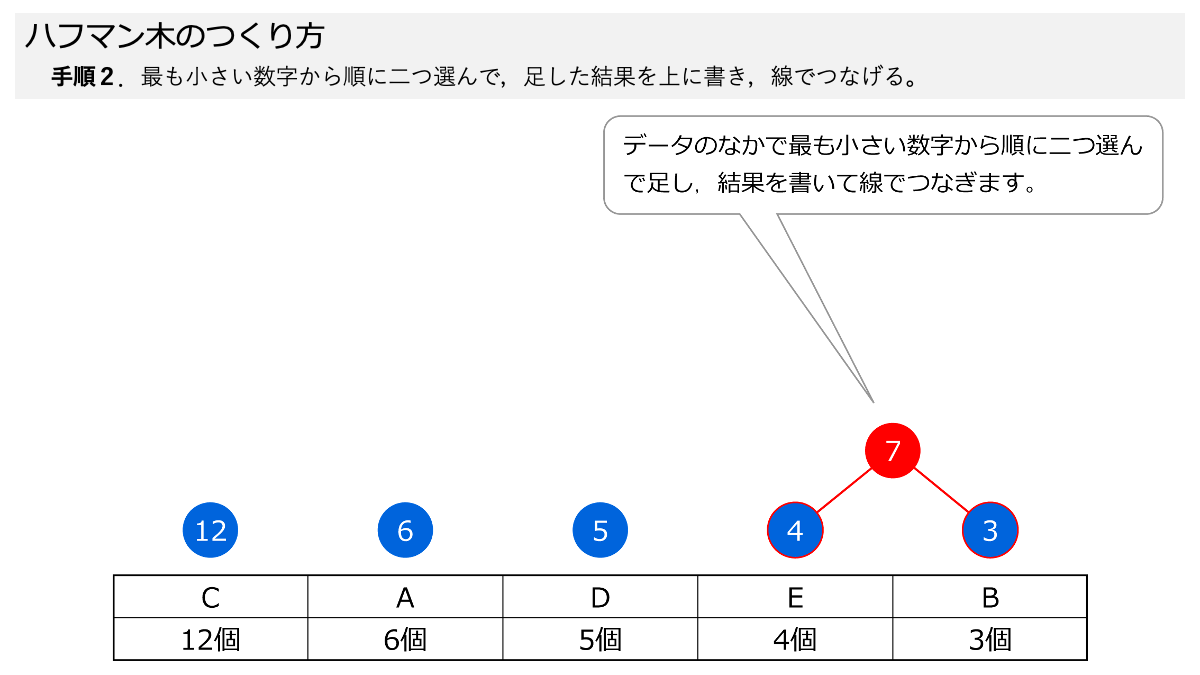
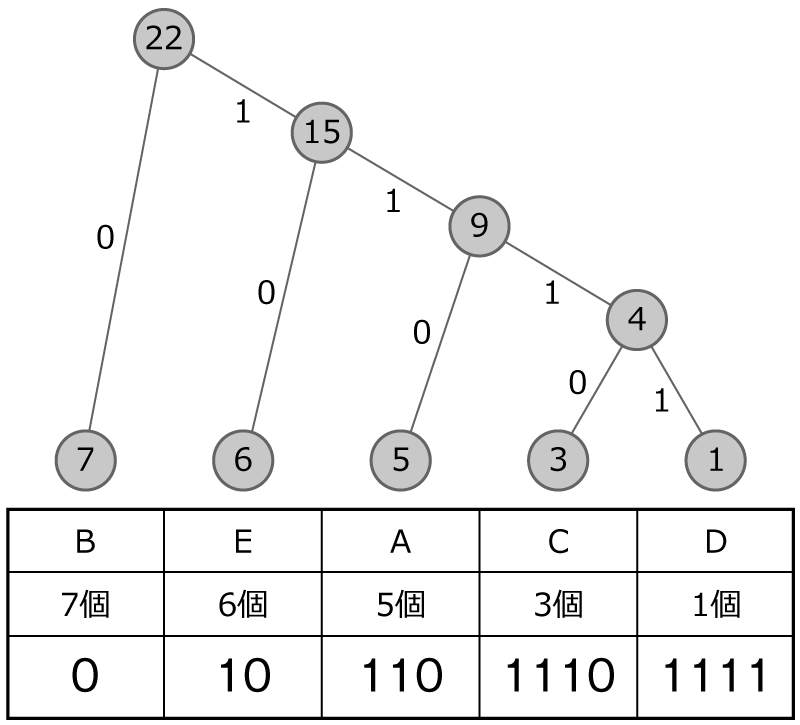
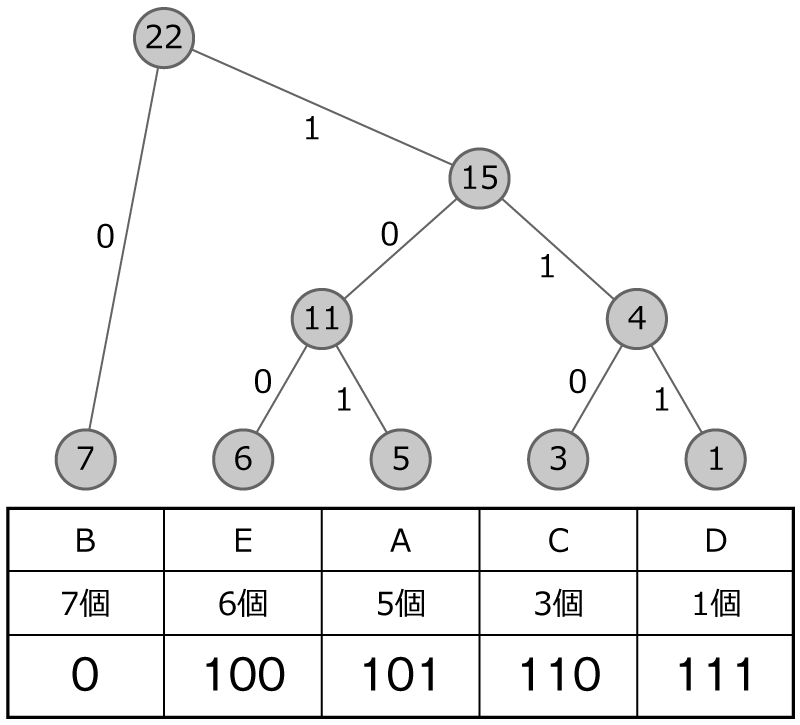
では,ちょっとハフマン木をつくる練習してみましょう。 次のハフマン木をつくってみてください。 個数も整理してますのでこの表をもとに考えてみてください。
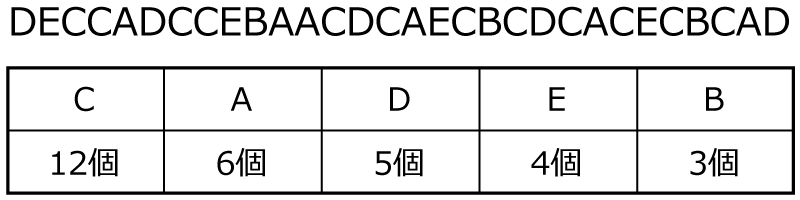
まずは,手順1で,データが多い順に丸を並べます!
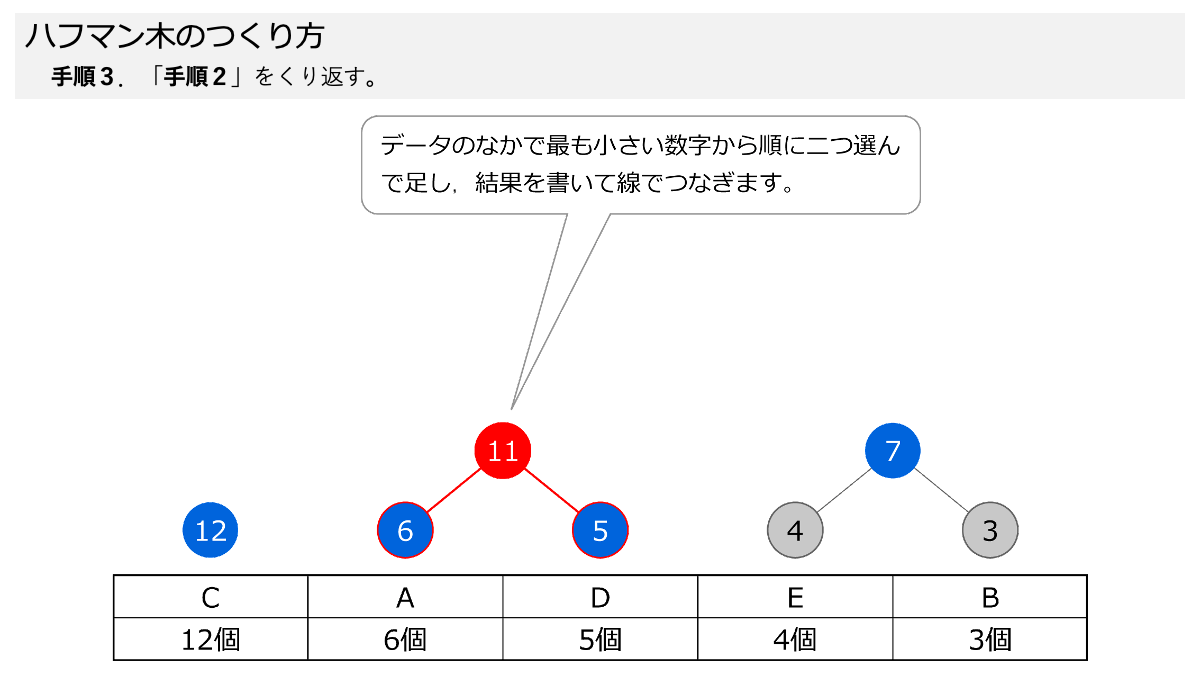
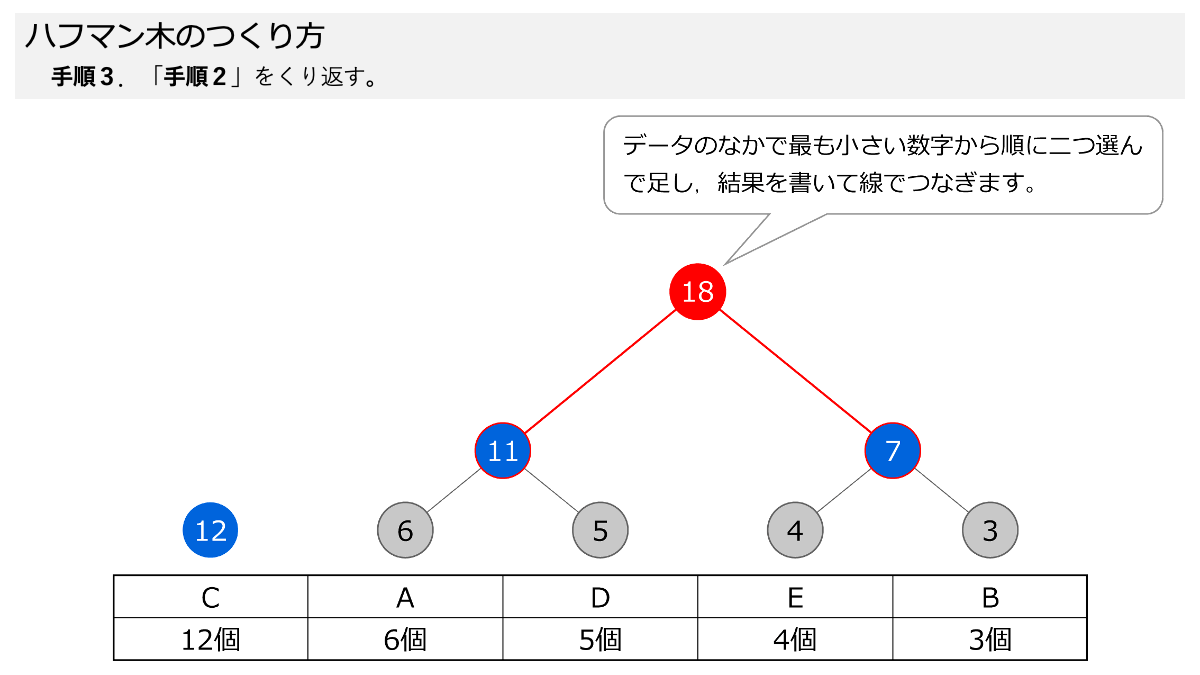
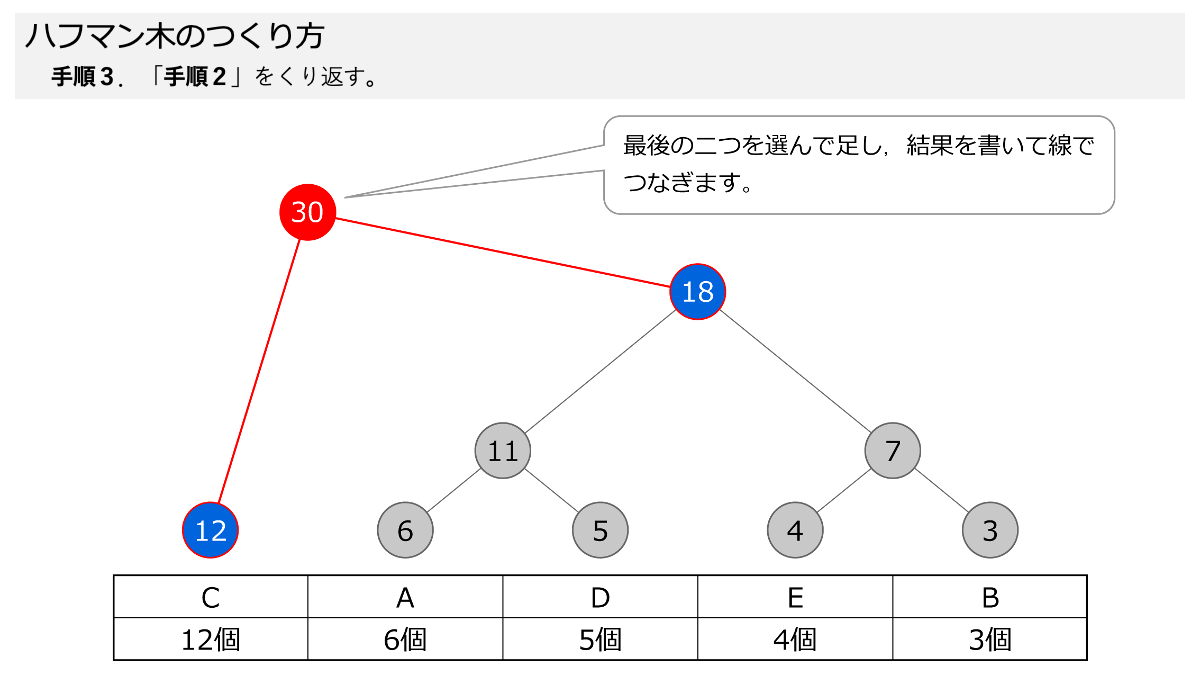
手順2と手順3で,小さい数字から順に二つ選んで,足して,その数を上の丸に書いてつなげます!
その通り!いい感じです!手順2と手順3をスライドにしてますので,ページをめくって手順を確認してください。
木ができたので,次はどうしましょうか?
0・1を書き込みます!
その通りです!最後に符号化していきましょう。 手順5をスライドにしてますので,ページをめくって手順を確認してください。
おお!さっきと違う形のハフマン木になりました!
小さいものを選んでいくと,線がクロスになったり,同じ数字が出てきたりすることもあります。 そのときも同じルールでやっていけば,複数パターンの形になることもあります。
へー,そうなんですね!
どんな形になっても,ルールにしたがってつくれば,正確な木になります!慣れていくことが大事ですね!
はーい!
では,練習問題をやってみましょう!
assignment練習問題
次の文字列をハフマン符号化するときの,ハフマン木はどうなりますか? 次のなかから一つ選んでください。

-
label_outline選択肢1
not_interested 不正解!
-
label_outline選択肢2
not_interested 不正解!
-
label_outline選択肢3
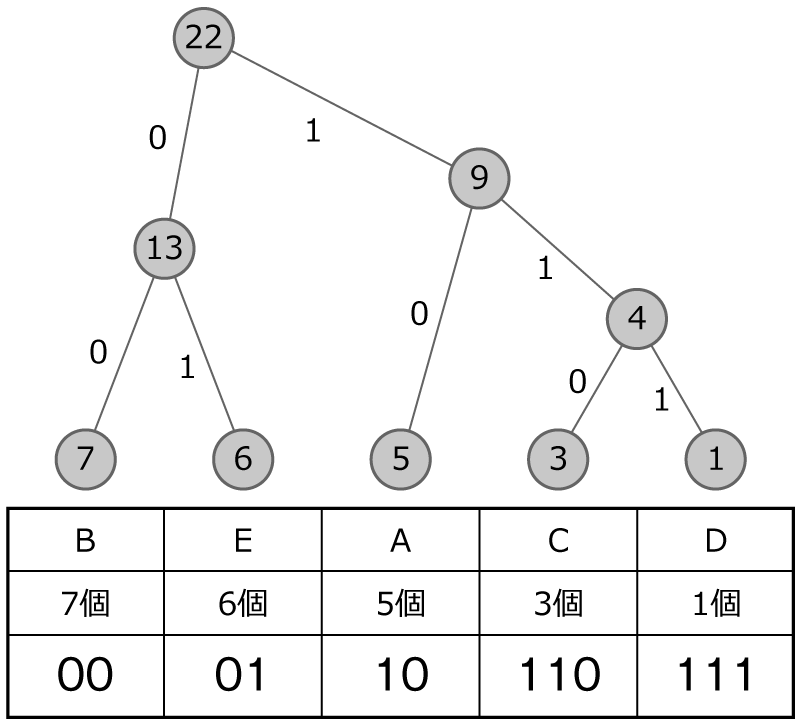
thumb_up 正解!
-
label_outline選択肢4
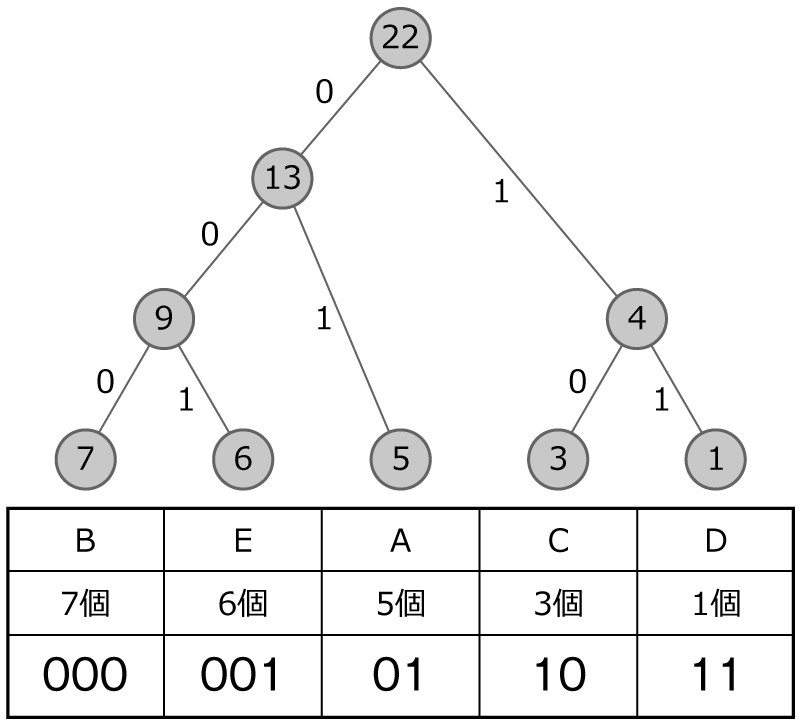
not_interested 不正解!